直接定位逻辑
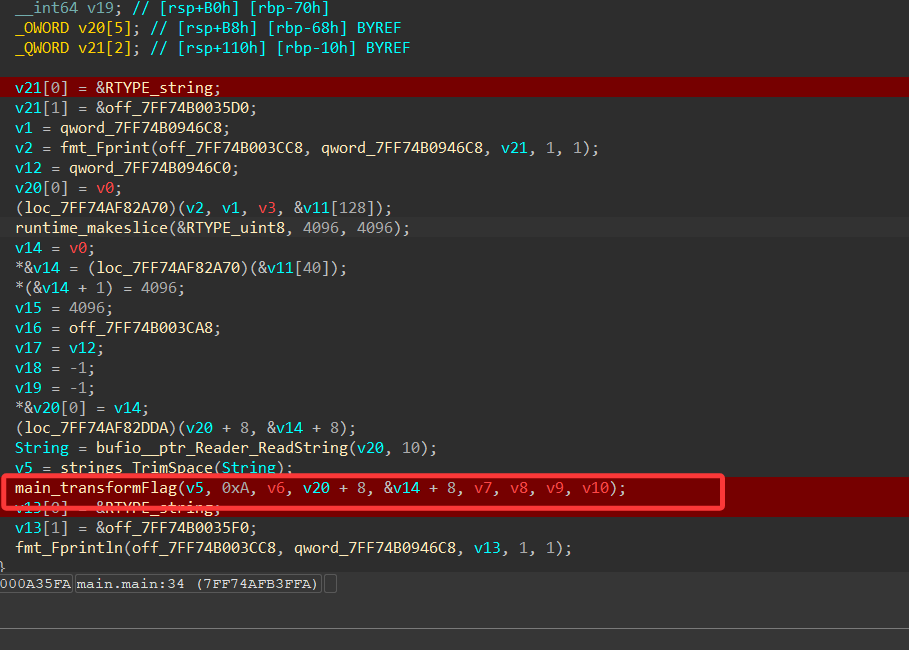
接下来是判断flag长度,输入41位数字,然后掐头去尾剩下36为数字,然后使用replace去掉输入里面的“-”
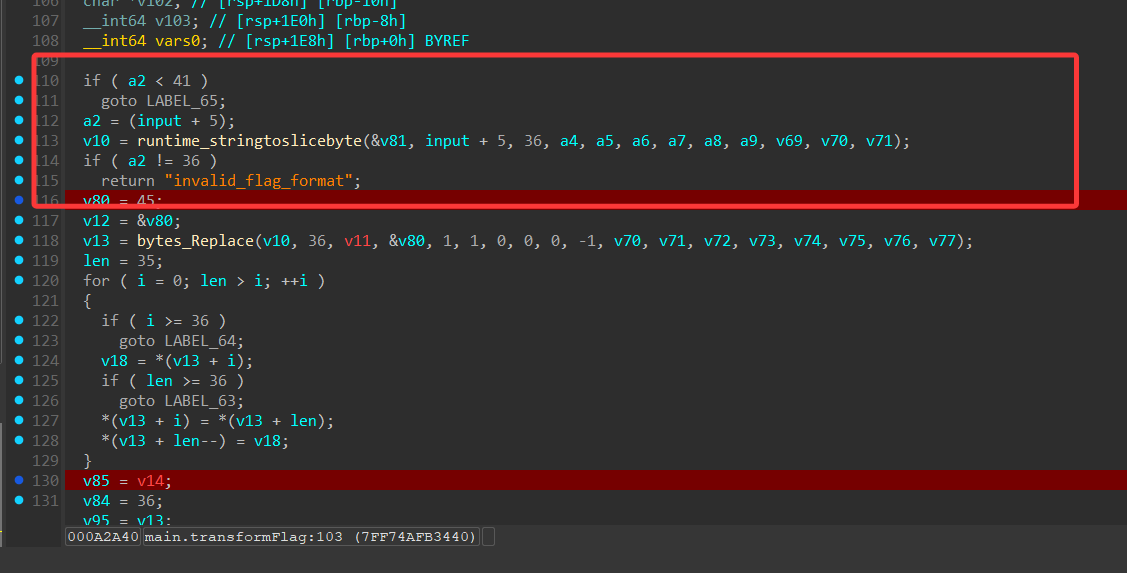
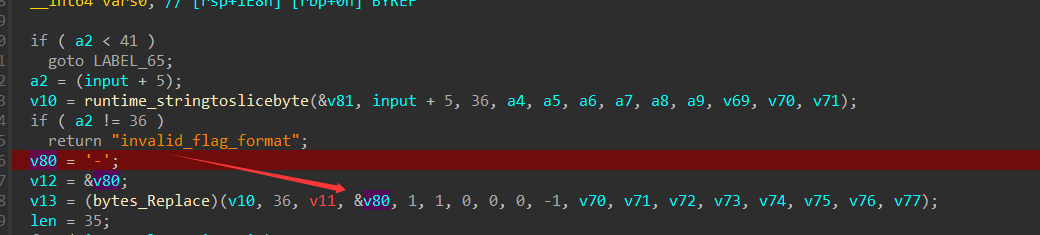
显然这里的算法逻辑已经为后话埋下了一个大坑,不过没问题待会儿再骂。
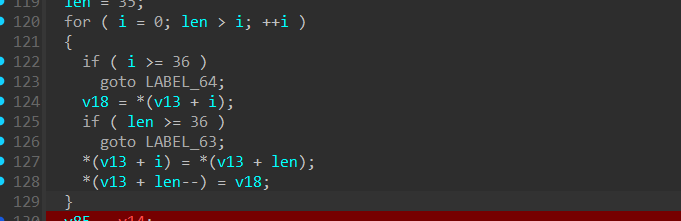
接下来典型的倒序算法
题目的主要逻辑也就是下面这一块了
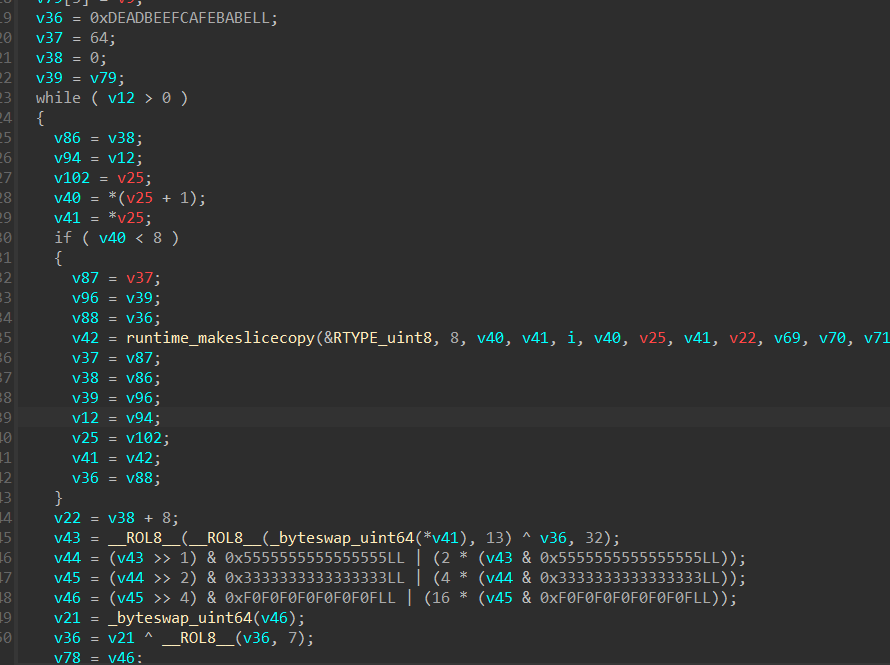
首先取8个字节为一个块,然后采用掩码交换位置。其实可以看看这些掩码的二进制你会有所发现
然后再通过swap从头到尾交换一边,最后异或v36这个v36每一轮都会被ROL更新,最后再Base32编码。

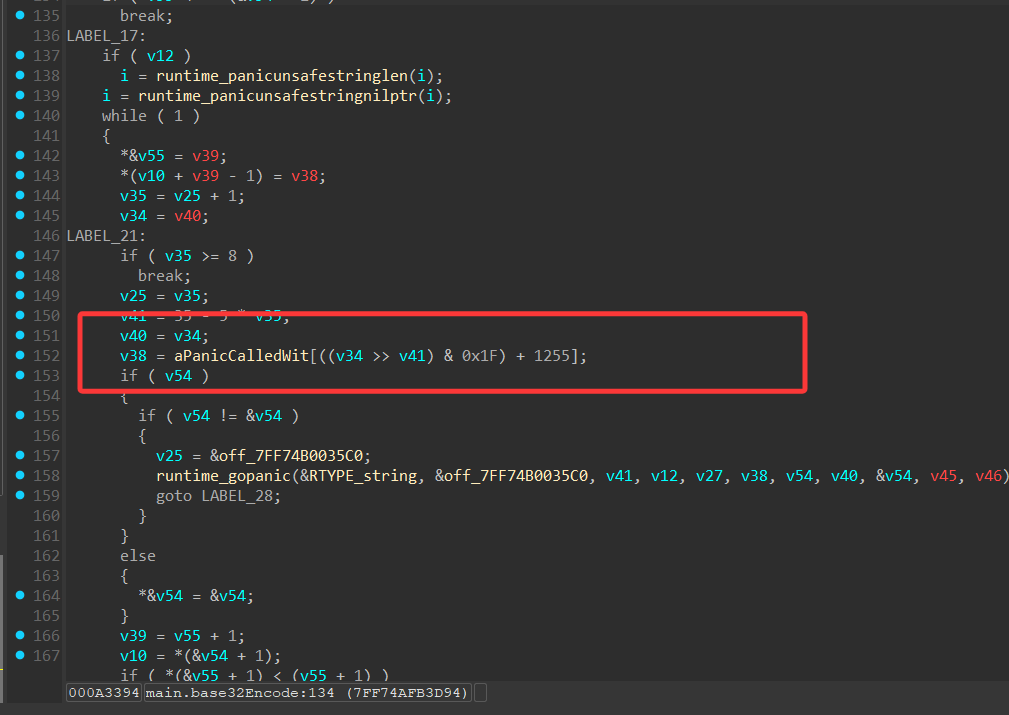
但是这个base32是有所变化的,在下面的aPaniccalledwit中可以看到取base32码表的过程,打断点直接调试
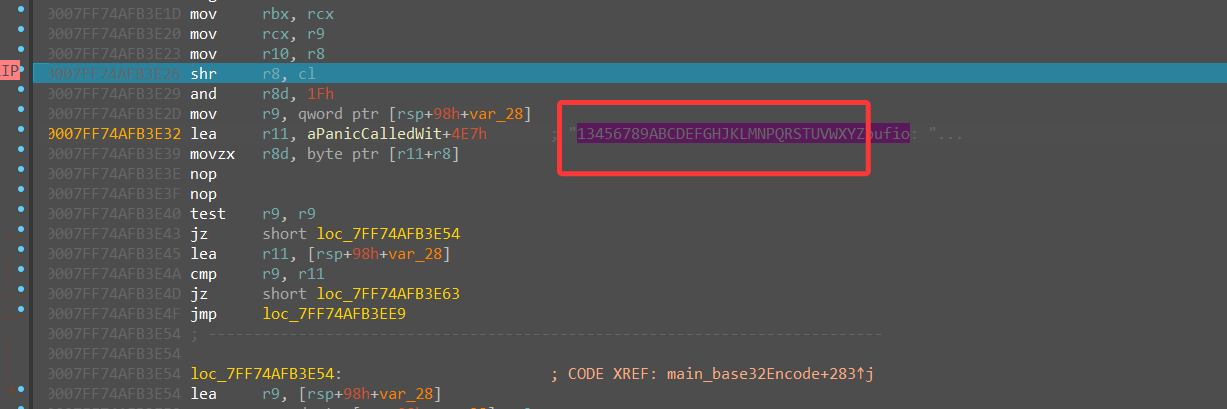
可以看到如下Base32编码表:13456789ABCDEFGHJKLMNPQRSTUVWXYZ
接下来复现还原算法:
MASK64 = (1 << 64) - 1
CUSTOM_B32_ALPHABET = "13456789ABCDEFGHJKLMNPQRSTUVWXYZ"
def rol(x, r):
r &= 63
return ((x << r) & MASK64) | ((x & MASK64) >> (64 - r))
def byteswap64(x):
return int.from_bytes(x.to_bytes(8, 'little')[::-1], 'little')
def bit_permute_steps(x):
x = ((x >> 1) & 0x5555555555555555) | ((x & 0x5555555555555555) << 1)
x = ((x >> 2) & 0x3333333333333333) | ((x & 0x3333333333333333) << 2)
x = ((x >> 4) & 0x0F0F0F0F0F0F0F0F) | ((x & 0x0F0F0F0F0F0F0F0F) << 4)
return x & MASK64
def custom_base32_encode(data: bytes) -> str:
bits = 0
bitlen = 0
out = []
for byte in data:
bits = (bits << 8) | byte
bitlen += 8
while bitlen >= 5:
bitlen -= 5
index = (bits >> bitlen) & 0x1F
out.append(CUSTOM_B32_ALPHABET[index])
if bitlen > 0:
index = (bits << (5 - bitlen)) & 0x1F
out.append(CUSTOM_B32_ALPHABET[index])
return ''.join(out)
def transform(inp: str) -> str:
if len(inp) < 41:
raise ValueError("input length must be at least 41")
s = inp[5:5+36]
s = s[::-1]
out_bytes = bytearray()
state = 0xDEADBEEFCAFEBABE
for i in range(0, len(s), 8):
blk = s[i:i+8].encode('latin1')
if len(blk) < 8:
blk = blk + b'\x00' * (8 - len(blk))
x = int.from_bytes(blk, 'big')
x = rol(x, 13)
x ^= state
x = rol(x, 32)
v46 = bit_permute_steps(x)
v21 = byteswap64(v46)
state = v21 ^ rol(state, 7)
out_bytes += (v46 & MASK64).to_bytes(8, 'little')
b32 = custom_base32_encode(bytes(out_bytes)).upper()
parts = [b32[i:i+6] for i in range(0, len(b32), 6)]
return '-'.join(parts)
if __name__ == "__main__":
test_inp = "1" * 41
print("output:", transform(test_inp))
经过调试和程序产生的一致。
题目的算法部分就是这么简单,但是好像在代码中没有看到比较部分。
在汇编中体现:
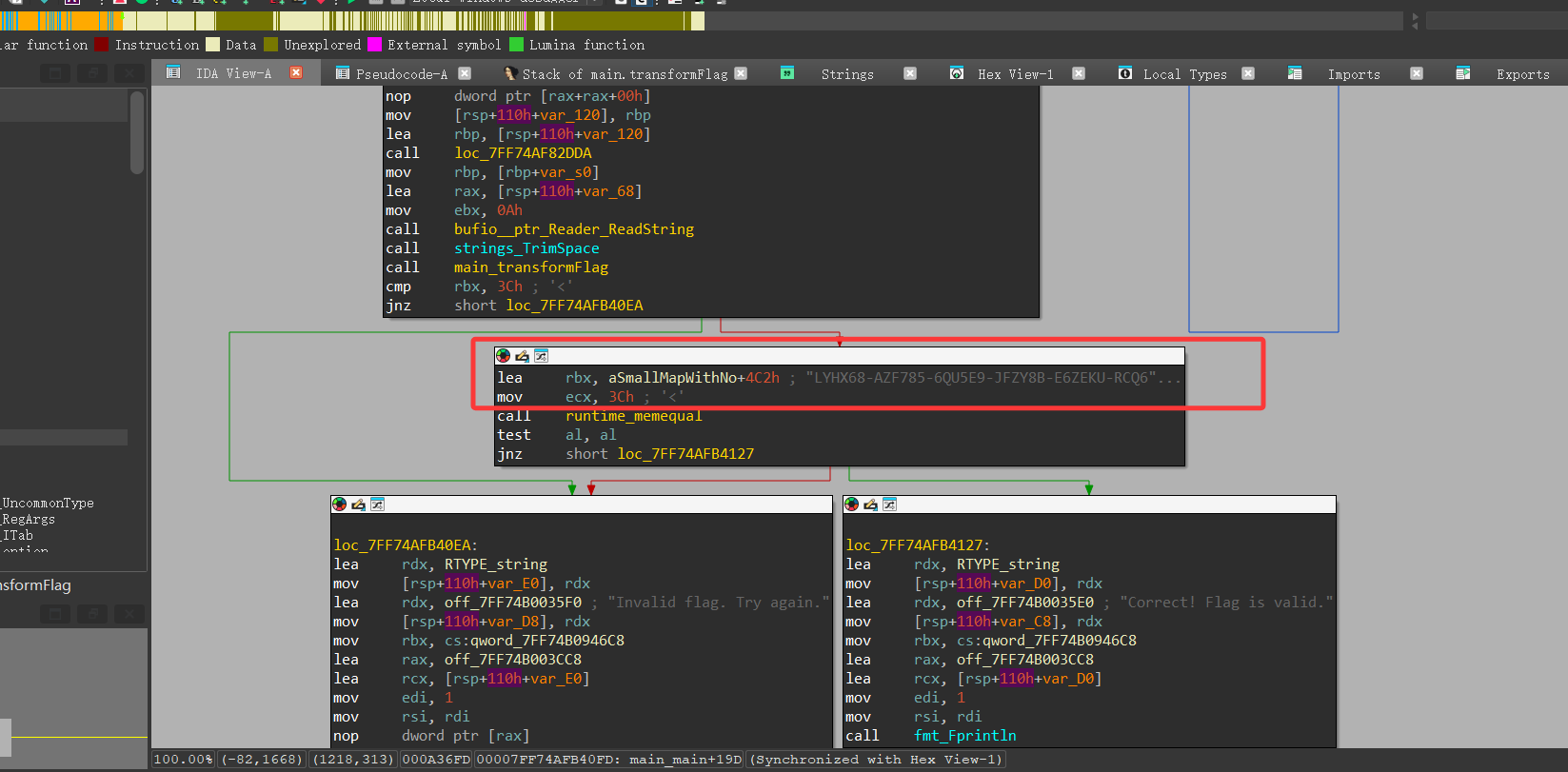
接下来就是反向解密了:
from typing import Tuple
MASK64 = (1 << 64) - 1
CUSTOM_B32_ALPHABET = "13456789ABCDEFGHJKLMNPQRSTUVWXYZ"
ALPHABET_MAP = {c: i for i, c in enumerate(CUSTOM_B32_ALPHABET)}
def rol(x: int, r: int) -> int:
r &= 63
return ((x << r) & MASK64) | ((x & MASK64) >> (64 - r))
def byteswap64(x: int) -> int:
return int.from_bytes(x.to_bytes(8, 'little')[::-1], 'little')
def bit_permute_steps(x: int) -> int:
x = ((x >> 1) & 0x5555555555555555) | ((x & 0x5555555555555555) << 1)
x &= MASK64
x = ((x >> 2) & 0x3333333333333333) | ((x & 0x3333333333333333) << 2)
x &= MASK64
x = ((x >> 4) & 0x0F0F0F0F0F0F0F0F) | ((x & 0x0F0F0F0F0F0F0F0F) << 4)
x &= MASK64
return x
def custom_base32_decode(s: str) -> bytes:
s = ''.join(ch for ch in s if ch not in '- \n\r\t')
bits = 0
bitlen = 0
out = bytearray()
for ch in s:
if ch not in ALPHABET_MAP:
raise ValueError(f"invalid base32 char: {ch!r}")
val = ALPHABET_MAP[ch]
bits = (bits << 5) | val
bitlen += 5
while bitlen >= 8:
bitlen -= 8
byte = (bits >> bitlen) & 0xFF
out.append(byte)
return bytes(out)
def inverse_transform(encoded: str) -> Tuple[str, bytes]:
raw = custom_base32_decode(encoded)
if len(raw) % 8 != 0:
raw = raw + b'\x00' * (8 - (len(raw) % 8))
nblocks = len(raw) // 8
state = 0xDEADBEEFCAFEBABE
recovered_bytes = bytearray()
for i in range(nblocks):
v46_le = raw[i*8:(i+1)*8]
v46 = int.from_bytes(v46_le, 'little')
x3 = bit_permute_steps(v46)
x2 = rol(x3, 32)
x1 = x2 ^ state
b_be = rol(x1, 64 - 13)
b_be &= MASK64
blk_be = b_be.to_bytes(8, 'big')
recovered_bytes += blk_be
v21 = byteswap64(v46)
state = v21 ^ rol(state, 7)
state &= MASK64
recovered36 = bytes(recovered_bytes[:36])
s_recovered = recovered36[::-1].decode('latin1')
return s_recovered, recovered36
if __name__ == "__main__":
encoded = "LYHX68-AZF785-6QU5E9-JFZY8B-E6ZEKU-RCQ65Y-QJB76Y-37MQXQ-5UJJ"
recovered_str, recovered_bytes = inverse_transform(encoded)
print("Encoded input: ", encoded)
print("Recovered 36-bytes (as latin1):", repr(recovered_str))
这题很抽象,解密出来时32位的可视字符,但是开局的时候被抹除了四根”-“这”-“应该补全在哪儿我们不得而知,只能猜测uuid格式。

但实际上在哪儿都是对的。
锐评就是垃圾题,flag都不收敛。
哎哟,这不SWDD么,几天不见这么拉了
rolling dog