codex-main Runtime 架构深拆:记忆、压缩、并行执行与卡死识别
本文面向 AppCheckMaster 的 APK 安全审计工作流,拆解 backend/codex-main 如何把一次“编码/审计任务”变成可持续、多轮、可压缩、可并行、可恢复的 runtime。
重点回答四个问题:
- codex-main 如何处理“记忆”:当前线程历史、长期 memories、外部上下文污染与引用回收。
- codex-main 如何做“压缩”:什么时候压缩、压缩后如何替换历史、为什么要重置模型连接。
- codex-main 如何做“并行执行”:模型协议里的并行工具调用如何落到 runtime 的并行闸门。
- codex-main 如何识别“长命令/卡死”:普通 shell 超时、输出管道卡死、长驻进程 yield 与后台会话。
本文所有架构图和时序图都使用 Mermaid 代码块。只要 Markdown 渲染器支持 Mermaid,图片就可以直接渲染,不依赖额外图片资源。
0. 总览:codex-main 是一个 turn runtime
codex-main 的核心不是“发一条 prompt 给模型”,而是一个围绕 turn 运行的 runtime:
Session持有线程级状态,例如历史、配置、工具注册、审批状态、长期记忆开关。TurnContext持有本轮请求的上下文,例如模型信息、工具集合、sandbox、审批策略。ModelClientSession持有本轮模型连接状态,例如 WebSocket 连接、previous_response_id、x-codex-turn-state。ContextManager持有短期对话历史,并负责送入模型前的历史归一化。ToolCallRuntime负责把模型输出的工具调用并行或串行执行。Compact负责在上下文变长时,把旧历史变成摘要或远端 compact 后的新历史。Memories负责跨线程长期记忆的后台抽取、合并、引用与污染控制。UnifiedExec负责长命令、交互式命令、后台命令的生命周期。
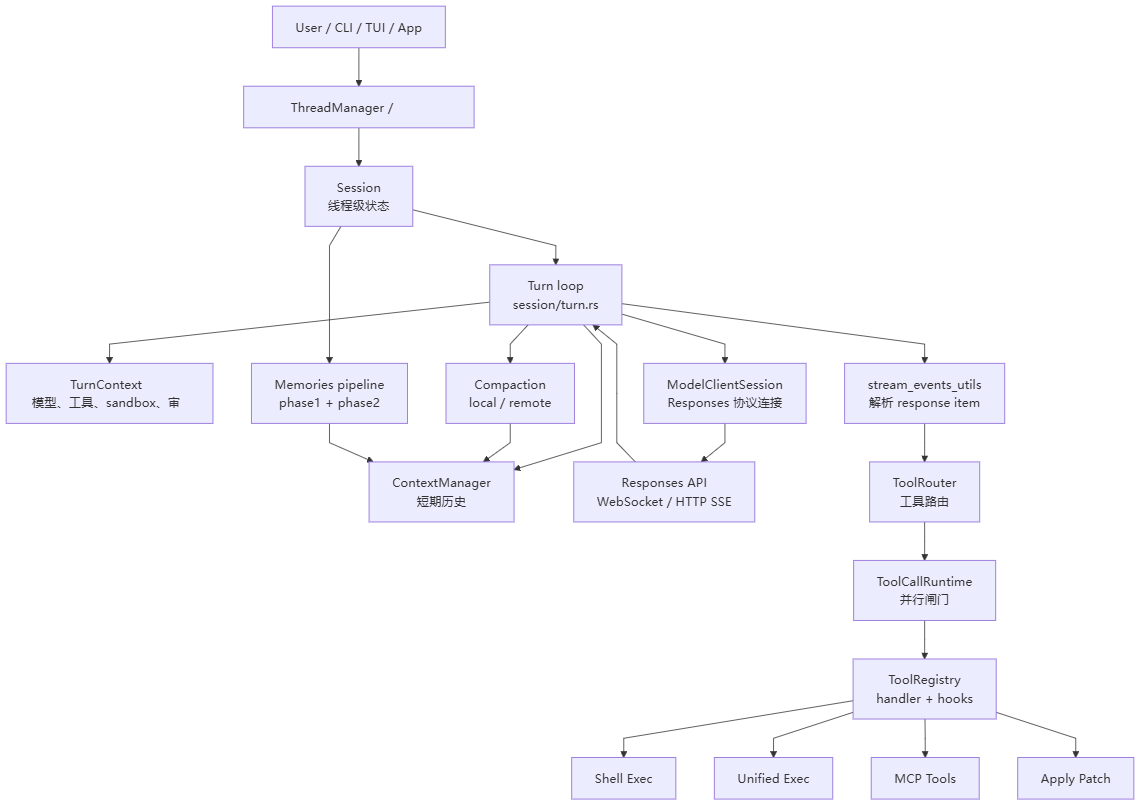
一个很实用的理解方式是:
turn 是最小调度单元,history 是模型输入的事实来源,tool runtime 是副作用执行层,compact/memories 是上下文生命支持系统。
1. 一次编码任务的主链路
一次编码或安全审计任务进入 codex-main 后,大致经历这些步骤:
- 构建
TurnContext,决定本轮用什么模型、什么工具、什么 sandbox、什么审批策略。 - 从
ContextManager取出模型可见历史,并做归一化。 - 进入
ModelClientSession.stream(...),优先使用 WebSocket,必要时回退 HTTP SSE。 - 模型流式返回 response item。
- 普通文本写入历史并发给前端。
- 工具调用交给
ToolRouter解析,再交给ToolCallRuntime执行。 - 工具输出回写历史。
- 如果需要 follow-up,再带着工具结果继续采样。
- 如果 token 触顶或模型切换导致上下文不足,触发 compact。
- 本轮结束后,runtime 持久化状态,并把可用信息提供给后续 turn。
关键代码节选:turn 负责串起所有 runtime 能力
源码位置:backend/codex-main/codex-rs/core/src/session/turn.rs
// 精简节选:采样前先判断是否需要压缩。
let auto_compact_limit = turn_context
.model_info
.auto_compact_token_limit()
.unwrap_or(i64::MAX);
let compacted = run_pre_sampling_compact(&sess, &turn_context).await;
if compacted {
client_session.reset_websocket_session();
}这段逻辑说明:压缩不是模型提示词里的“自觉行为”,而是 runtime 在采样前主动执行的上下文维护动作。压缩后要重置 WebSocket,因为历史被改写,旧的 previous_response_id / 增量上下文不再可靠。
// 精简节选:把历史转成模型输入。
let input = sess
.clone_history()
.await
.for_prompt(&turn_context.model_info.input_modalities);这里体现了 codex-main 的一个重要设计:模型输入不是从终端 transcript 拼出来的,而是从 runtime-owned history 投影出来的。
// 精简节选:工具输出后,如果还需要模型继续推理,就继续一轮采样。
if token_limit_reached && needs_follow_up {
run_auto_compact(
sess.clone(),
turn_context.clone(),
client_session.clone(),
auto_compact_limit,
InitialContextInjection::BeforeLastUserMessage,
CompactReason::ContextLimit,
CompactTrigger::MidTurn,
)
.await?;
client_session.reset_websocket_session();
continue;
}这段是“编码任务不会因为中途上下文满了就死掉”的关键。模型刚调用完工具、还需要看结果继续做事时,如果上下文触顶,runtime 会先 compact,再继续 follow-up。
2. 记忆系统:短期历史 + 长期 memories
codex-main 的“记忆”分两层:
- 短期历史:当前线程的
ResponseItem列表,由ContextManager管理。它决定下一次模型到底能看到什么。 - 长期 memories:跨线程后台抽取和合并的记忆,由
memoriespipeline 和 state DB 管理。它解决“另一个会话里学到的偏好、项目事实、工作方式如何复用”的问题。

2.1 短期历史:ContextManager 是模型输入的事实来源
源码位置:backend/codex-main/codex-rs/core/src/context_manager/history.rs
pub(crate) struct ContextManager {
/// Items are stored oldest first.
items: Vec<ResponseItem>,
/// Incremented any time history is rewritten, for example compaction.
history_version: u64,
token_info: Option<TokenUsageInfo>,
reference_context_item: Option<TurnContextItem>,
}字段解释:
items:模型可见历史的原始条目,按时间从旧到新保存。history_version:历史被重写时递增,例如 compact、rollback。它让其他组件知道“之前看到的历史快照已经过期”。token_info:最近一次 token 估算或实际使用情况,用于判断是否需要 compact。reference_context_item:压缩后保留的上下文基线,用于避免把旧 context 重复注入。
pub(crate) fn for_prompt(mut self, input_modalities: &[InputModality]) -> Vec<ResponseItem> {
self.normalize_history(input_modalities);
self.items
.retain(|item| !matches!(item, ResponseItem::GhostSnapshot { .. }));
self.items
}for_prompt() 是短期记忆进入模型前的最后一道门。它做两件事:
- 调用
normalize_history(...)修正历史结构,例如移除没有对应调用的 orphan tool output。 - 移除
GhostSnapshot这类 runtime 内部辅助项,避免污染模型上下文。
fn normalize_history(&mut self, input_modalities: &[InputModality]) {
// 精简说明:保证 tool call 与 tool output 成对存在;
// 如果模型不支持图片输入,则剥离图片内容;
// 移除不应暴露给模型的内部条目。
}这一步很重要。安全审计任务经常会调用 shell、移动端、Frida、MCP、图片查看等工具,如果历史没有规范化,模型可能看到“孤儿工具输出”或不支持的输入模态,导致协议错误或推理偏移。
2.2 长期 memories:两阶段后台管线
源码位置:
backend/codex-main/codex-rs/core/src/memories/README.mdbackend/codex-main/codex-rs/core/src/memories/mod.rsbackend/codex-main/codex-rs/state/src/runtime/memories.rs
memories pipeline 在 root session 启动时运行,但有几个前置条件:
- 不是 ephemeral session。
- 不是 sub-agent。
- 配置启用了 memory。
- state DB 可用。
- 线程没有被外部上下文污染到需要禁用 memory 的状态。
核心两阶段如下:
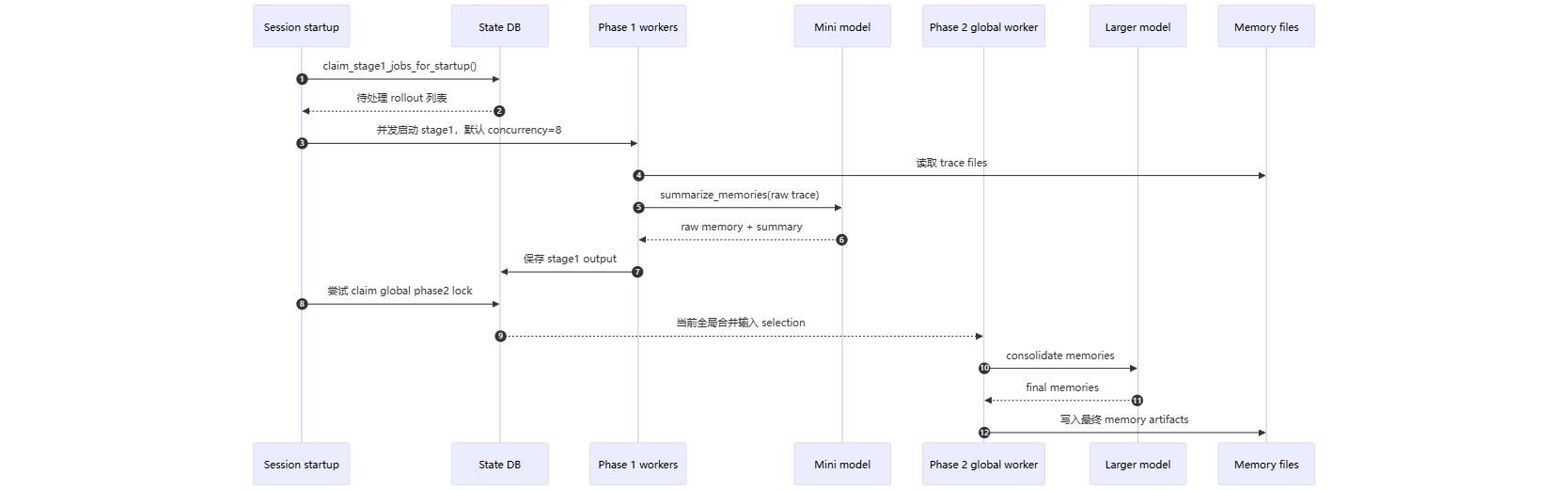
代码节选:
// core/src/memories/mod.rs,精简节选。
mod phase_one {
pub const MODEL: &str = "gpt-5.4-mini";
pub const CONCURRENCY_LIMIT: usize = 8;
}
mod phase_two {
pub const MODEL: &str = "gpt-5.4";
pub const JOB_HEARTBEAT_SECONDS: u64 = 90;
}设计含义:
- Phase 1 是大量小任务,适合用更轻模型并发抽取。
- Phase 2 是全局合并,影响长期记忆质量,使用更强模型并通过 global lock 保证只有一个合并者。
JOB_HEARTBEAT_SECONDS和 lease 机制让后台任务不会因为进程崩溃永久占锁。
// state/src/runtime/memories.rs,精简节选。
pub fn claim_stage1_jobs_for_startup(...) {
// 过滤当前线程、禁用 memory 的线程、太新的线程、已处理且未过期的线程。
// 按 updated_at 排序,控制 scan_limit,再领取 job lease。
}这体现了长期记忆的一个优化原则:
不重新总结所有历史,只总结“值得更新”的 rollout,并通过 lease 避免重复工作。
2.3 外部上下文污染:memory 不是无条件学习
源码位置:
backend/codex-main/codex-rs/core/src/mcp_tool_call.rsbackend/codex-main/codex-rs/core/src/stream_events_utils.rs
当线程使用了外部 MCP 上下文,runtime 可能把当前线程标记为 memory polluted:
// 精简节选。
if config.memory.disable_on_external_context {
mark_thread_memory_mode_polluted(...).await;
}这对安全审计尤其重要。MCP 可能读取外部系统、私有资源或临时上下文,如果无脑写进长期 memory,会污染后续项目和后续审计。
2.4 memory citation:长期记忆也要可追踪
源码位置:backend/codex-main/codex-rs/core/src/memories/citations.rs
模型引用 memory 时会产生 memory citation。runtime 会解析 citation,记录哪些 stage1 output 被使用过。这样 Phase 2 可以根据使用频率、最近使用时间、过期策略选择合并输入。

效果:
- 经常被引用的记忆更容易保留。
- 长期未使用的记忆更容易被淘汰。
- 合并输入不是无限增长,而是带使用反馈的受控集合。
3. 压缩系统:上下文生命支持
codex-main 的压缩不是简单“总结一下聊天记录”。它有明确触发点、历史替换策略、协议重置动作。
触发点主要有四类:
- Pre-turn compact:采样前发现 token 使用超过 auto compact limit。
- Mid-turn compact:工具调用后仍需 follow-up,但 token limit 已触顶。
- Model downshift compact:切到上下文更小的模型前,发现当前历史太大。
- Manual compact:用户或上层显式触发。
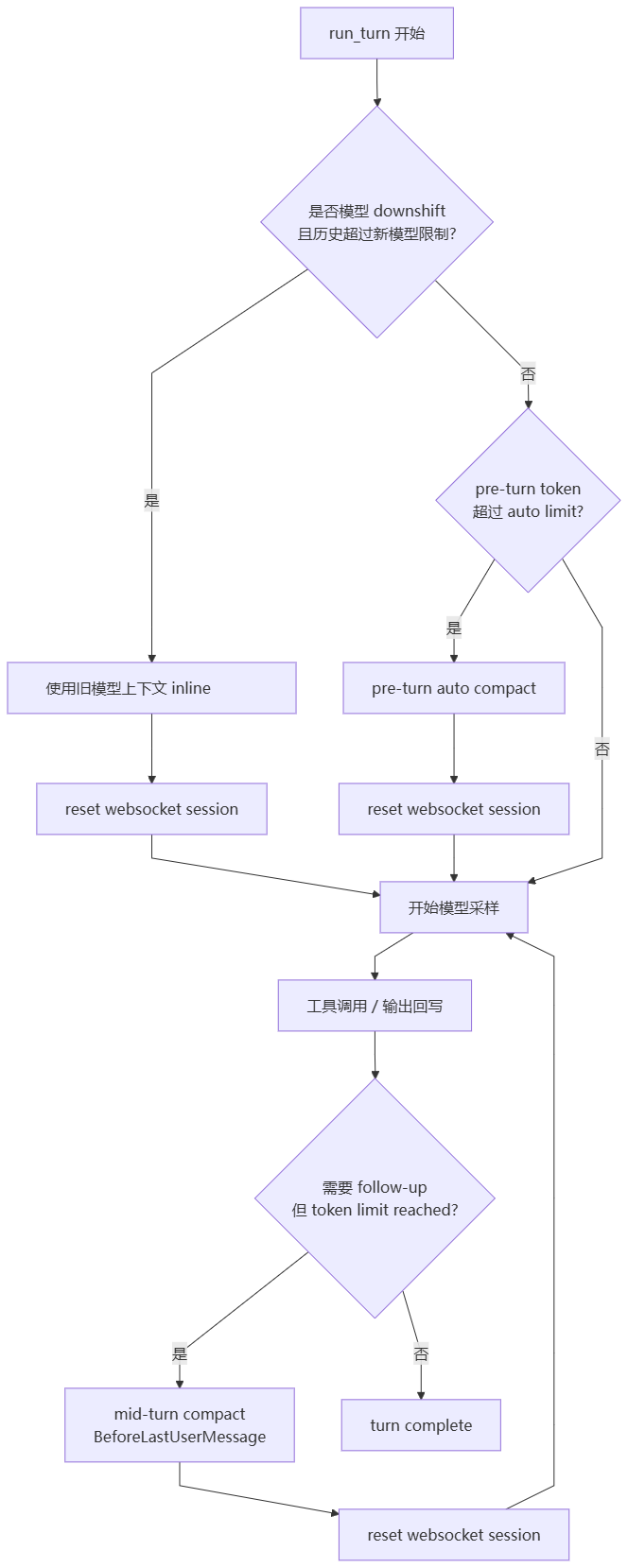
3.1 本地 compact:模型自己总结历史
源码位置:backend/codex-main/codex-rs/core/src/compact.rs
pub enum InitialContextInjection {
DoNotInject,
BeforeLastUserMessage,
}InitialContextInjection 的含义:
DoNotInject:pre-turn 或 manual compact 时,不需要把 initial context 插回用户消息前。BeforeLastUserMessage:mid-turn compact 时,需要把 compact 后的上下文插到最后一条用户消息前。这样模型继续 follow-up 时,仍能看到“用户刚才要做什么”。
// 精简节选:compact 期间复用同一个 client session。
let client_session = model_client.create_session();
loop {
let turn_input = build_compact_prompt(history);
let stream = client_session.stream(&turn_input).await?;
if context_too_large {
history.remove_first_item();
continue;
}
break;
}这里有一个不明显但很关键的缓存优化:
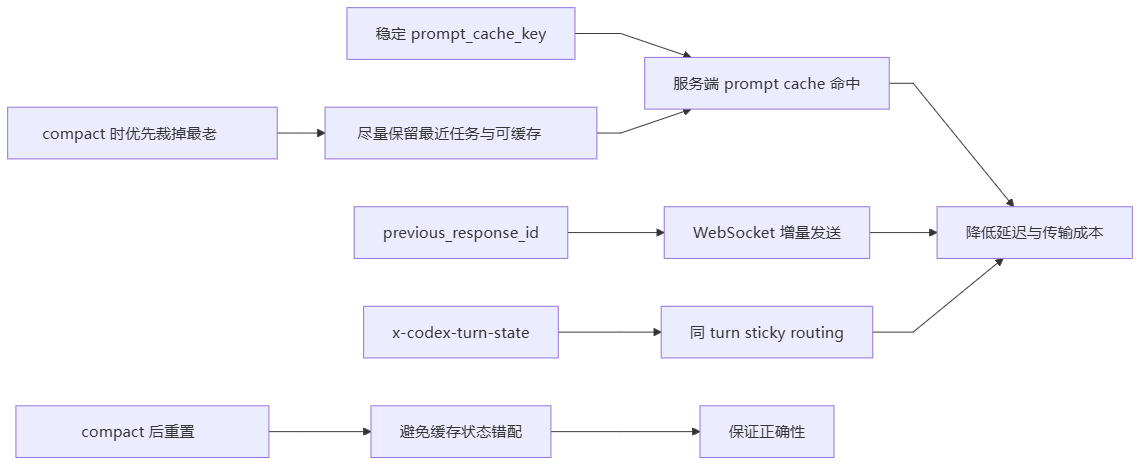
compact 过程中如果上下文仍然太大,优先删除最老的 history item,而不是重写最近上下文。这样能尽量保留 prompt cache 前缀和最新任务语义。
// 精简节选:生成 summary 后替换历史。
let compacted_item = CompactedItem {
message: summary_text.clone(),
replacement_history: Some(new_history.clone()),
};
sess.replace_compacted_history(
new_history,
reference_context_item,
compacted_item,
)
.await;
client_session.reset_websocket_session();
sess.recompute_token_usage(&turn_context).await;压缩后的行为不是“追加一条总结”,而是“用新历史替换旧历史”。这能避免旧上下文继续占 token,也让后续 token 估算变准确。
3.2 远端 compact:由 provider 原生压缩历史
源码位置:backend/codex-main/codex-rs/core/src/compact_remote.rs
当 provider 支持 remote compaction,runtime 会走远端 compact endpoint:
// 精简节选。
if provider.supports_remote_compaction {
model_client
.compact_conversation_history(history, ...)
.await?;
}远端 compact 的结果还要经过过滤:
fn should_keep_compacted_history_item(item: &ResponseItem) -> bool {
// 保留 assistant、compaction item、必要 warning / summary user message。
// 丢弃 developer message 和陈旧重复 context。
}为什么要过滤?
- provider 返回的是“压缩后的对话历史”,但并不代表每个条目都适合重新注入。
- developer message、陈旧 context、重复 baseline 都可能破坏 runtime 对上下文的所有权。
- 过滤后再
replace_compacted_history(...),确保历史仍符合 codex-main 的协议不变量。
3.3 压缩后的协议重置
压缩会重写 history,因此必须重置模型连接状态:
client_session.reset_websocket_session();原因:
- WebSocket 增量请求依赖
previous_response_id。 previous_response_id暗含“服务端还记得上一轮上下文”。- compact 后本地历史已经变成新投影,继续复用旧增量状态可能造成服务端上下文与本地上下文不一致。
这是 codex-main 在“缓存命中”和“正确性”之间的取舍:能复用时尽量复用,一旦 history rewrite,就主动断开增量链路。
4. 模型协议与缓存命中
codex-main 对 Responses API 的使用有几个专门服务于稳定性和缓存命中的设计:
prompt_cache_key:通常使用 conversation id,让同一线程命中服务端 prompt cache。previous_response_id:WebSocket 增量请求只发送新增 item,减少重复传输。x-codex-turn-state:服务端返回后,后续请求带回,帮助同一 turn 的 sticky routing。enable_request_compression:请求体压缩,降低长上下文传输成本。prewarm_websocket:提前建立 WebSocket 并用generate=false预热,降低下一次真实采样延迟。
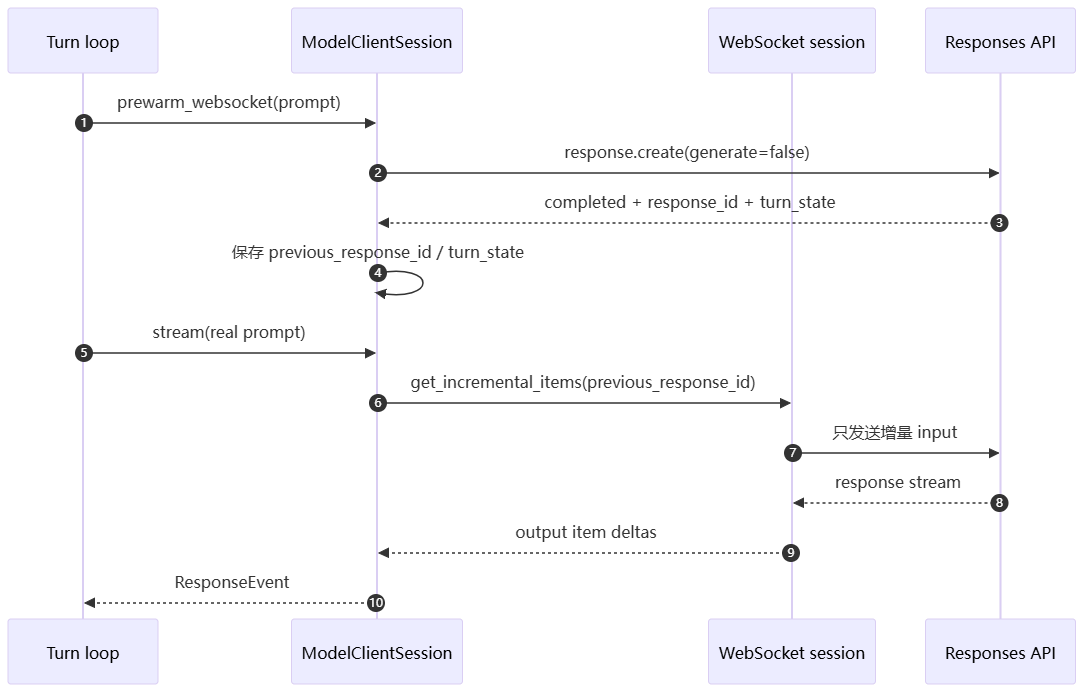
源码位置:backend/codex-main/codex-rs/core/src/client.rs
pub struct ModelClientSession {
client: ModelClient,
websocket_session: Mutex<Option<WebsocketSession>>,
cache_websocket_session_on_drop: bool,
turn_state: OnceLock<String>,
}字段解释:
websocket_session:当前 turn 可复用的 WebSocket 连接。cache_websocket_session_on_drop:本轮结束时是否把连接放回 client state,供下一轮复用。turn_state:从响应头x-codex-turn-state读到的服务端状态,用于同一 turn 的请求黏性。
fn build_responses_headers(&self, ...) -> HeaderMap {
let mut headers = HeaderMap::new();
if let Some(turn_state) = self.turn_state.get() {
headers.insert("x-codex-turn-state", turn_state.parse()?);
}
headers
}turn_state 不是模型记忆,而是协议层的服务端路由/状态提示。它的生命周期应该比 thread memory 短得多,主要服务于同一 turn 内的连续请求。
// 精简节选。
request.prompt_cache_key = Some(conversation_id);
request.parallel_tool_calls = prompt.parallel_tool_calls;
request.previous_response_id = websocket_session.last_response_id();这几个字段把模型协议和 runtime 对齐起来:
- cache key 稳定,才能命中长 prompt 前缀缓存。
- previous response id 存在,才能走增量输入。
- parallel tool calls 打开,模型才可以在同一轮输出多个可并发工具调用。
缓存命中优化总结
5. 并行执行:模型并行调用到 runtime 并行闸门
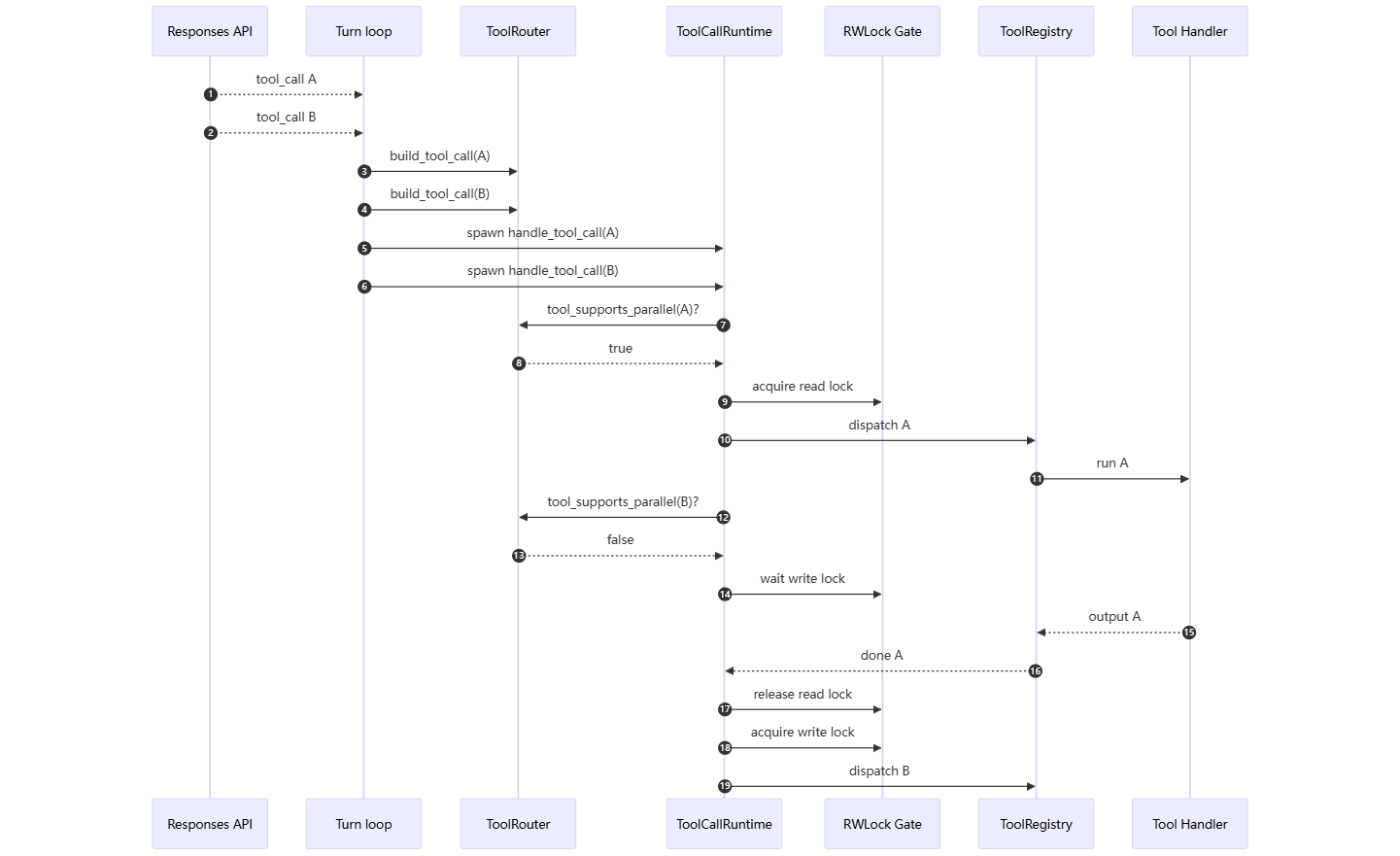
codex-main 的并行不是“所有工具都随便并发”。它分三层控制:
- 模型协议层:请求里允许
parallel_tool_calls。 - 路由层:
ToolRouter判断某个工具是否支持并行。 - runtime 层:
ToolCallRuntime用读写锁实现“并行安全工具可一起跑,非并行工具独占”。

5.1 模型协议打开 parallel tool calls
源码位置:
backend/codex-main/codex-rs/core/src/client_common.rsbackend/codex-main/codex-rs/core/src/client.rs
pub struct Prompt {
pub input: Vec<ResponseItem>,
pub tools: Vec<Tool>,
pub parallel_tool_calls: bool,
}// 精简节选。
request.parallel_tool_calls = prompt.parallel_tool_calls;这个字段只是告诉模型“你可以并行规划工具调用”。真正能否并发执行,还要看 runtime。
5.2 stream_events_utils 把模型 item 变成工具 future
源码位置:backend/codex-main/codex-rs/core/src/stream_events_utils.rs
pub(crate) struct OutputItemResult {
pub needs_follow_up: bool,
pub tool_future: Option<BoxFuture<'static, ToolCallOutput>>,
}// 精简节选。
let call = ctx.tool_router.build_tool_call(response_item)?;
record_completed_response_item(...).await;
let cancellation_token = ctx.cancellation_token.child_token();
let tool_future = ctx
.tool_runtime
.clone()
.handle_tool_call(call, cancellation_token);
OutputItemResult {
needs_follow_up: true,
tool_future: Some(tool_future),
}含义:
- 模型一旦输出工具调用,runtime 先把这条 tool call 记录进 history。
- 然后把工具调用包装成 future。
needs_follow_up = true表示工具输出回写后,模型还需要继续看结果并推理。
5.3 ToolCallRuntime 的读写锁并行模型
源码位置:backend/codex-main/codex-rs/core/src/tools/parallel.rs
pub(crate) struct ToolCallRuntime {
router: Arc<ToolRouter>,
session: Arc<Session>,
turn_context: Arc<TurnContext>,
tracker: SharedTurnDiffTracker,
parallel_execution: Arc<RwLock<()>>,
}// 精简节选:并行安全工具拿读锁,独占工具拿写锁。
let supports_parallel = self.router.tool_supports_parallel(&call);
let _guard = if supports_parallel {
Either::Left(lock.read().await)
} else {
Either::Right(lock.write().await)
};
router
.dispatch_tool_call_with_code_mode_result(...)
.await这段是并行执行的核心:
- 支持并行的工具拿 read lock,多个 read lock 可同时存在。
- 不支持并行的工具拿 write lock,write lock 会等待所有 read lock 结束,也会阻止其他 read/write lock。
- 因此,runtime 可以并发执行“只读、独立、安全”的工具,同时保证 mutating 或高风险工具串行。
5.4 ToolRegistry 负责最终执行和副作用门控
源码位置:backend/codex-main/codex-rs/core/src/tools/registry.rs
// 精简节选。
let is_mutating = handler.is_mutating(&call, context).await?;
if is_mutating {
turn.tool_call_gate.wait_ready().await;
}
let output = handler.handle(call, context).await;这层解决的是另一个问题:即使工具支持并行,真正执行前仍要判断是否 mutating、是否需要等待审批、是否要跑 pre/post hook、是否要写 telemetry。
5.5 为什么安全审计里这很重要
安全审计任务里有很多天然适合并行的工作:
- 多文件代码阅读。
- 多规则静态匹配。
- 多个只读 shell 查询。
- 多个 MCP resource 读取。
- 多个 APK 反编译产物索引检索。
但也有很多必须串行或独占的工作:
- 修改文件。
- 删除临时目录。
- 安装/卸载 APK。
- 启停 Frida server。
- 改变设备前台 app 状态。
codex-main 的读写锁并行模型正好适合 AppCheckMaster:让“读取和分析”尽量并发,让“副作用和设备状态变化”保持受控。
6. 长命令与卡死识别
codex-main 对“命令卡死”的处理分两套机制:
- 普通
shell/shell_command:一次性命令,使用 timeout、kill process group、IO drain timeout、输出上限。 unified_exec:长命令或交互式命令,使用 yield time、后台 process id、状态机、输出通知、后续 wait/write_stdin。
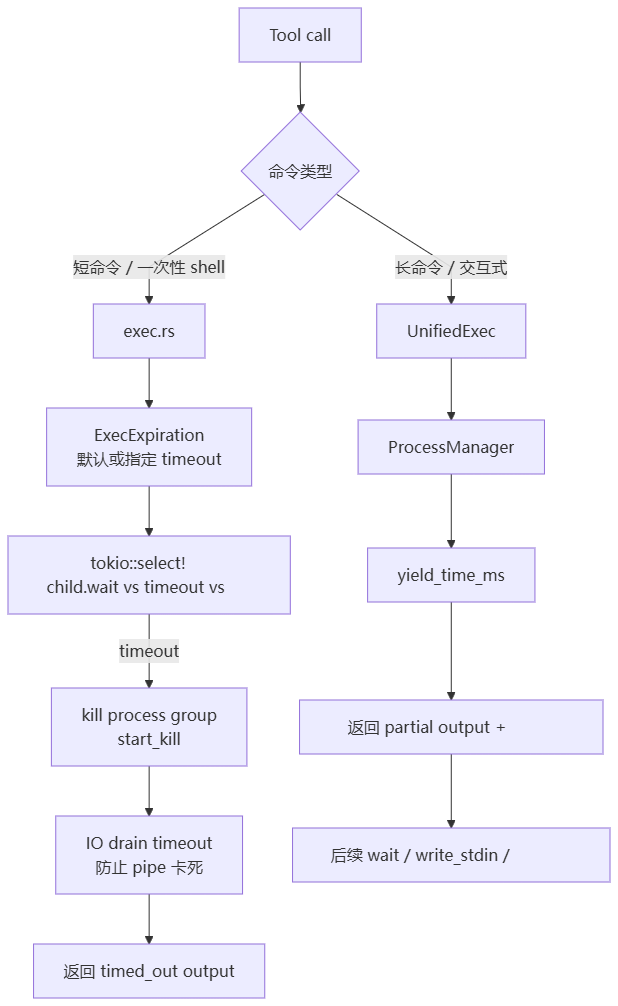
6.1 普通 shell:timeout 不是唯一防线
源码位置:backend/codex-main/codex-rs/core/src/exec.rs
关键常量:
pub const DEFAULT_EXEC_COMMAND_TIMEOUT_MS: u64 = 10_000;
pub const EXEC_TIMEOUT_EXIT_CODE: i32 = 124;
const IO_DRAIN_TIMEOUT_MS: u64 = 2_000;
const MAX_EXEC_OUTPUT_DELTAS_PER_CALL: usize = 10_000;解释:
- 默认命令 10 秒超时。
- 超时退出码按 shell 习惯用
124。 - kill 后最多等 2 秒 drain stdout/stderr,防止输出管道永远不关闭。
- 单次工具调用最多发送 10000 个 output delta,避免流式输出刷爆事件通道。
pub enum ExecExpiration {
Timeout(Duration),
DefaultTimeout,
Cancellation(CancellationToken),
}ExecExpiration 把三类终止条件抽象成一个等待对象:
- 用户显式
timeout_ms。 - 默认 timeout。
- 上层取消 token,例如用户中断 turn。
// 精简节选:等待子进程、超时或 ctrl-c。
let (exit_status, timed_out) = tokio::select! {
status_result = child.wait() => {
(status_result?, false)
}
_ = &mut expiration_wait => {
kill_child_process_group(&mut child)?;
child.start_kill()?;
(ExitStatus::from_raw(EXEC_TIMEOUT_EXIT_CODE), true)
}
_ = ctrl_c() => {
kill_child_process_group(&mut child)?;
child.start_kill()?;
(ExitStatus::from_raw(1), false)
}
};这解决“命令本身不退出”的问题。但还有一个更隐蔽的问题:命令被 kill 后,stdout/stderr pipe 可能仍不关闭。
// 精简节选:kill 后读取任务也不能无限等。
match tokio::time::timeout(
capture_policy.io_drain_timeout(),
&mut *output_handle,
)
.await
{
Ok(output) => output?,
Err(_) => {
output_handle.abort();
StreamOutput::default()
}
}为什么需要 IO drain timeout?
有些命令会创建孙进程,孙进程继承 stdout/stderr。父进程被 kill 后,pipe 仍然被孙进程持有,读取任务会一直等 EOF。如果没有 drain timeout,agent 会表现得像“明明 kill 了命令但自己卡住了”。
6.2 输出读取:既要防爆,也要防背压
源码位置:backend/codex-main/codex-rs/core/src/exec.rs
// 精简节选。
while let Ok(bytes_read) = reader.read(&mut buf).await {
if bytes_read == 0 {
break;
}
maybe_emit_output_delta(&buf[..bytes_read]).await;
append_capped(&mut captured_output, &buf[..bytes_read], output_cap);
}输出处理有两条线:
- 流式 delta 发给前端,帮助用户看到命令还活着。
- 本地 capped buffer 保留头尾或限定大小,避免巨大日志把上下文和内存打爆。
即使输出超过 cap,runtime 仍会继续 drain pipe,防止子进程因为 stdout/stderr pipe 写满而阻塞。
6.3 unified_exec:长命令不等于卡死
普通 shell 适合 rg、git status、cargo test 这类应该结束的命令。长命令则不同,例如:
- 启动 dev server。
- 跑持续日志 tail。
- 长时间 fuzz / scan。
- 交互式 shell。
- 移动端实时监控。
这些命令“没结束”不一定是卡死,所以 unified_exec 采用 yield 模型。
源码位置:
backend/codex-main/codex-rs/core/src/tools/handlers/unified_exec.rsbackend/codex-main/codex-rs/core/src/unified_exec/process_manager.rsbackend/codex-main/codex-rs/core/src/unified_exec/process.rs
pub struct ExecCommandArgs {
pub cmd: Vec<String>,
pub yield_time_ms: Option<u64>,
pub max_output_tokens: Option<u64>,
pub sandbox_permissions: Option<SandboxPermissions>,
pub timeout_ms: Option<u64>,
}yield_time_ms 是 unified_exec 的关键。它不是命令总超时,而是“本次工具调用最多等多久再把控制权还给模型”。
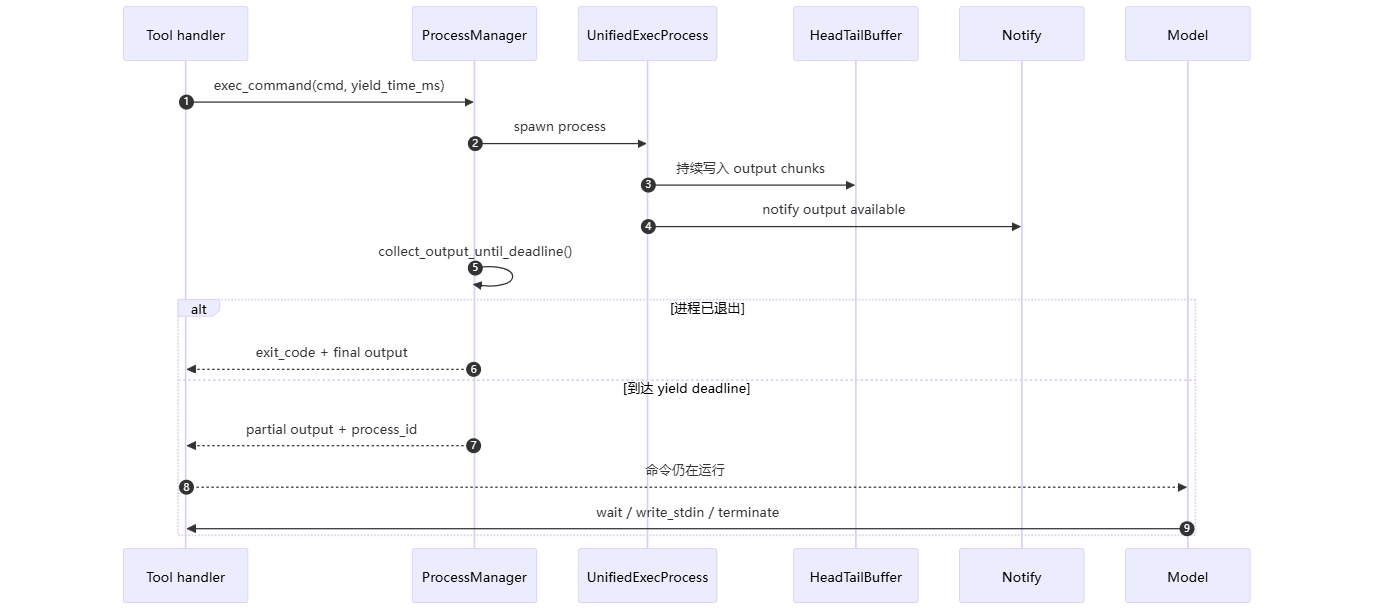
collect_output_until_deadline(...) 会等待这些事件之一:
- 有新输出到达。
- 进程退出。
- 输出关闭。
- cancellation token 触发。
- 到达本次 yield deadline。
它不是 sleep 轮询,而是通过 Notify 和状态 watch 被动唤醒,避免 CPU 忙等。
6.4 ProcessManager 防止后台进程无限堆积
源码位置:backend/codex-main/codex-rs/core/src/unified_exec/process_manager.rs
// 精简节选。
fn prune_processes_if_needed(&mut self) {
// 保护最近的若干进程;
// 优先清理已退出的 LRU;
// 如果仍超限,再清理最久未使用的进程。
}长命令能后台运行,就必须有后台资源回收。否则一次审计里启动多个扫描、tail、server,很容易把 runtime 拖死。
6.5 ProcessState:区分退出、失败、仍运行
源码位置:backend/codex-main/codex-rs/core/src/unified_exec/process_state.rs
pub struct ProcessState {
pub has_exited: bool,
pub exit_code: Option<i32>,
pub failure_message: Option<String>,
}状态解释:
has_exited = false:进程仍在运行,返回 partial output 不代表失败。has_exited = true, exit_code = Some(code):正常拿到退出码。failure_message = Some(...):runtime 层执行失败,例如 exec server 错误、输出流异常。
这让模型可以做正确决策:
- 命令没结束但有
process_id:可以 wait。 - 输出里提示需要输入:可以 write_stdin。
- 明确失败:换策略或报告错误。
- 超时或无输出:可以 terminate 或改用更窄命令。
7. 长命令“卡死”的识别策略总结
codex-main 没有只靠一个“超时秒表”判断卡死,而是按命令类型分层:
| 场景 | 机制 | 优化结果 |
|---|---|---|
| 普通命令不退出 | ExecExpiration + tokio::select! |
到点 kill,不阻塞 turn |
| 子进程/孙进程导致 pipe 不关闭 | IO_DRAIN_TIMEOUT_MS |
kill 后最多 drain 一小段时间,避免 agent 自己挂死 |
| 输出过大 | output cap + delta cap | 防止内存、事件流、模型上下文爆炸 |
| 输出很快 | 持续 drain pipe | 防止 stdout/stderr 背压导致进程假死 |
| 长驻进程 | unified_exec yield_time_ms |
到点返回 partial output,进程后台继续 |
| 交互式命令 | write_stdin + process id |
模型可以继续喂输入,而不是重启命令 |
| 后台进程过多 | LRU prune | 控制资源占用 |
| 用户中断 | cancellation token | 工具 future 返回 aborted output |
8. 源码调用链索引
8.1 一次 turn 的主调用链
Session / CodexThread
-> session/turn.rs::run_turn
-> run_pre_sampling_compact
-> ContextManager::for_prompt
-> ModelClientSession::stream
-> WebSocket stream or HTTP SSE stream
-> stream_events_utils::handle_output_item_done
-> ToolRouter::build_tool_call
-> ToolCallRuntime::handle_tool_call
-> ToolRegistry::dispatch_any
-> drain_in_flight
-> maybe run_auto_compact if token limit reached8.2 短期历史调用链
ContextManager
-> items: Vec<ResponseItem>
-> normalize_history
-> for_prompt
-> estimate_token_count_with_base_instructions
-> replace_compacted_history / rollback9.3 长期 memories 调用链
Session startup
-> memories::pipeline
-> state::runtime::memories::claim_stage1_jobs_for_startup
-> memory_trace::build_memories_from_trace_files
-> ModelClient::summarize_memories
-> record_stage1_output_usage
-> get_phase2_input_selection
-> phase2 global consolidation8.4 compact 调用链
session/turn.rs
-> run_pre_sampling_compact
-> maybe_run_previous_model_inline_compact
-> run_auto_compact
-> compact_remote::run_inline_remote_auto_compact_task
-> compact::run_inline_auto_compact_task
-> run_compact_task_inner
-> Session::replace_compacted_history
-> ModelClientSession::reset_websocket_session8.5 并行工具调用链
Responses API stream
-> response.output_item.done
-> stream_events_utils::handle_output_item_done
-> ToolRouter::build_tool_call
-> ToolCallRuntime::handle_tool_call
-> tool_supports_parallel
-> RwLock read/write gate
-> ToolRouter::dispatch_tool_call_with_code_mode_result
-> ToolRegistry::dispatch_any
-> specific handler8.6 普通 shell 防卡死调用链
ShellHandler
-> process_exec_tool_call
-> exec
-> spawn_child_async
-> consume_output
-> tokio::select!(child.wait, expiration, ctrl-c)
-> kill_child_process_group on timeout
-> read_output stdout/stderr
-> IO drain timeout8.7 unified_exec 长命令调用链
UnifiedExecHandler
-> ProcessManager::allocate_process_id
-> ProcessManager::exec_command
-> UnifiedExecProcess::spawn
-> HeadTailBuffer
-> Notify output waiters
-> collect_output_until_deadline
-> return partial output + process_id
-> wait / write_stdin / terminate9. 名词速查
| 名词 | 含义 |
|---|---|
turn |
一次用户输入到模型完成响应的 runtime 调度周期。内部可能包含多次模型采样和多个工具调用。 |
Session |
线程级运行状态,拥有 history、配置、工具、审批、memory 状态。 |
TurnContext |
本轮不可或少的上下文快照,例如模型、工具、sandbox、审批策略。 |
ContextManager |
当前线程短期历史的 owner,负责归一化和投影为模型输入。 |
ResponseItem |
Responses API 的统一历史条目,包括用户消息、助手消息、工具调用、工具输出等。 |
history_version |
history 被重写后的版本号,compact/rollback 等会递增。 |
reference_context_item |
compact 后保留的上下文基线,避免重复注入旧上下文。 |
ModelClientSession |
本轮模型协议会话,管理 WebSocket、previous_response_id、turn_state。 |
turn_state |
服务端通过 x-codex-turn-state 返回的短生命周期协议状态,用于同一 turn 的请求黏性。 |
prompt_cache_key |
提示缓存 key,通常按 conversation id 稳定设置,帮助服务端 cache 命中。 |
previous_response_id |
WebSocket 增量请求的锚点,让下一次只发送新增 item。 |
parallel_tool_calls |
模型协议字段,允许模型在同一轮规划多个工具调用。 |
ToolRouter |
把模型输出 item 解析成具体工具调用,并判断工具属性。 |
ToolCallRuntime |
工具调用执行 runtime,用读写锁控制并行与独占。 |
ToolRegistry |
工具 handler 注册、mutating 判断、hook、telemetry 和最终 dispatch。 |
Compact |
压缩历史的 runtime 机制,包括本地总结和远端 provider compact。 |
InitialContextInjection |
compact 后 initial context 的插入策略,mid-turn 时常用 BeforeLastUserMessage。 |
Memory polluted |
当前线程因外部上下文等原因不适合写入长期 memory。 |
ExecExpiration |
普通命令的结束条件抽象,包括超时、默认超时、取消。 |
IO_DRAIN_TIMEOUT_MS |
kill 后等待 stdout/stderr drain 的上限,防止 pipe 不关闭导致 runtime 卡住。 |
unified_exec |
长命令/交互式命令 runtime,支持后台 process、partial output、wait/write_stdin。 |
yield_time_ms |
unified_exec 单次工具调用等待输出的时间上限,不等同于命令总超时。 |
HeadTailBuffer |
长输出保留结构,避免无限日志占满内存,同时保留有用头尾信息。 |